MapR sprints ahead on performance
Analytical DBMS: HBase; supports Drill, Hive, Impala, Shark, and other (non-DBMS) SQL-on-Hadoop options.
In-memory DBMS: MapR touts in-memory performance through (nib-DBMS) open-source projects Drill and Shark.
Hadoop distributions: MapR M3, MapR M5, MapR M7.
Stream-processing technology: MapR supports streaming analysis through Storm and through an integration with Informatica HParser.
Hardware/software systems: Hardware configurations available through partners including Cisco, HP, IBM, and NetApp.
Analytical DBMS: HBase; supports Drill, Hive, Impala, Shark, and other (non-DBMS) SQL-on-Hadoop options.
In-memory DBMS: MapR touts in-memory performance through (nib-DBMS) open-source projects Drill and Shark.
Hadoop distributions: MapR M3, MapR M5, MapR M7.
Stream-processing technology: MapR supports streaming analysis through Storm and through an integration with Informatica HParser.
Hardware/software systems: Hardware configurations available through partners including Cisco, HP, IBM, and NetApp.
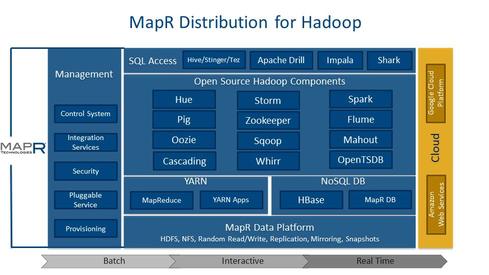
MapR marches to the beat of its own drum, replacing bits and pieces of the Hadoop framework to deliver higher performance or to fill gaps in functionality. Early on, it replaced HDFS with an alternative based on the Network File System (NFS) to ensure high availability. In a tie between NFS and Informatica HParser software introduced in 2012, MapR introduced an option for stream processing on top of Hadoop. The 2013 MapR M7 Hadoop distribution addresses weakness in HBase by doing away with region servers, table splits and merges, and data-compaction steps. MapR also implemented its own architecture for snapshotting, high availability, and system recovery.
With M7, MapR also introduced optional LucidWorks Search software on top of Hadoop for building out recommendation engines, fraud-detection, and predictive applications. MapR promotes Apache Drill as its SQL-on-Hadoop option of choice, but it pragmatically touts open-source and commercial alternatives including Apache Hive, Impala, Shark-on-Spark, Hadapt and others, perhaps responding to rivals who slam MapR's go-it-alone ways.
The community addresses Hadoop's squeakiest wheels at its own pace, but MapR seems to thrive on moving ahead with commercial alternatives with the promise of better performance.
Comments
Post a Comment